htcondenser¶
What is it?¶
htcondenser is a simple library for submitting simple jobs & DAGs on the Bristol machines.
It was designed to allow easy setting up of jobs and deployment on worker nodes, whilst following the Code of Conduct without the user worrying too much about writing custom scripts, or copying across files to HDFS.
Note that this probably won’t work for more custom or complicated workflows, but may be a useful starting point.
What do I need?¶
An area on /hdfs/users that you have read/write permission. Python
>= 2.6 (default on soolin), but untested with Python 3.
For developers: To build the docs, you’ll need
sphinx
(pip install sphinx). flake8 and pep8 are also useful tools, and are available via pip or conda.
How do I install it?¶
There are 2 different ways of installing. Both ensure that the package is found globally.
1 via pip¶
This is the easiest and recommended method, but requires you to have pip installed. The easiest way is via conda: either having your own miniconda installation, or simply adding the common one (/software/miniconda/bin/pip) to PATH:
export PATH=/software/miniconda/bin:$PATH
Note that pip is not required for using the library, just installing it.
You can then install the library by doing:
pip install -U --user git+https://github.com/raggleton/htcondenser.git
Unfortunately, the executable scripts are not added to PATH by default. To do this, add the following to your ~/.bashrc:
export PATH=$HOME/.local/bin:$PATH
Then do source ~/.bashrc for this to take effect.
2 by hand¶
Clone this repo
Run
./setup.sh. Since is required every time you log in, you can add it to your~/.bashrc:source <path to htcondenser>/setup.sh
N.B master branch should always be usable. I have added some tags; these are more “milestones” to show a collection of changes (e.g. new functionality, serioud bugfix).
How do I update it?¶
If you installed it via pip, ismply run the same command as before:
pip install -U --user git+https://github.com/raggleton/htcondenser.git
If you cloned it locally first, cd into the cloned directory and simply git pull origin master.
How do I get started?¶
Look in the examples directory. There are several directories, each
designed to show off some features:
- simple_job/simple_job.py:
Submits 3 jobs, each running a simple shell script, but with
different arguments. Designed to show off how to use the
htcondenserclasses. - simple_exe_job/simple_exe_job.py:
Submits a job using a user-compiled exe,
showsize. Before submission, you must compile the exe:gcc showsize.c -o showsize. Test it runs ok by doing:./showsize. - simple_root6_job/simple_root6job.py: Run ROOT6 over a macro to produce a PDF and TFile with a TTree. (TO FIX: Requires existing ROOT setup)
- simple_cmssw_job/simple_cmssw_job.py:
Setup a CMSSW environment and run
edmDumpEventContentinside it. For a CRAB-alternative, see cmsRunCondor - dag_example/dag_example.py: Run a DAG (directed-acyclic-graph) - this allows you to schedule jobs that rely on other jobs to run first.
- dag_example_common/dag_example_common.py has a similar setup but shows the use of
common_input_filesarg to save time/space.
For more info/background, see Usage.
Monitoring jobs/DAGs¶
If you submit your jobs as a DAG, then there is a simple monitoring tools, DAGstatus.
See DAGstatus for more details.
A bit more detail¶
The aim of this library is to make submitting jobs to HTCondor a breeze. In particular, it is designed to make the setting up of libraries & programs, as well as transport of any input/output files, as simple as possible, whilst respecting conventions about files on HDFS, etc.
Each job is represented by a Job object. A group of Jobs is
governed by a JobSet object. All Jobs in the group share
common settings: they run the same executable, same setup commands,
output to same log directory, and require the same resources. 1
JobSet = 1 HTCondor job description file. Individual Jobs
within a JobSet can have different arguments, and different
input/output files.
For DAGs an additional DAGMan class is utilised. Jobs must also be
added to the DAGMan object, with optional arguments to specify which
jobs must run as a prerequisite. This still retains the
Job/JobSet structure as before for simpler jobs, to simplify the
sharing of common parameters and to reduce the number of HTCondor submit
files.
Aside: DAGs (Directed Acyclic Graphs)
Essentially, a way of tying jobs together, with the requirement that some jobs can only run once their predecessors have run successfully.
Graph: collection of nodes joined together by edges. Nodes
represent jobs, and edges represent hierarchy. (Note, not the
y = sin(x) type of graph.)
Directed: edges between nodes have a direction. e.g.
A ->- B means A precedes B, so B will only run once A has
finished successfully.
Acyclic: the graph cannot have cycles, e.g.
A ->- B ->- C ->- A.
For an example see the diamond DAG (examples/dag_example):
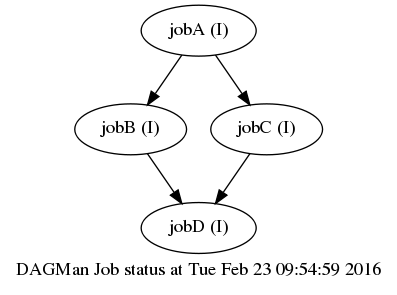
There, jobB and jobC can only run once jobA has completed. Similarly, jobD can only run once jobB and jobC have completed.
Full documentation¶
Common pitfalls¶
ERROR: proxy has expired: you need to renew your Grid certificate:voms-proxy-init -voms cms.DAG submits, but then immediately disappears from running condor_q -dag: check your .dagman.out file. At the end, you will see something like:
Warning: failed to get attribute DAGNodeName ERROR: log file /users/ab12345/htcondenser/examples/dag_example_common/./diamond.dag.nodes.log is on NFS. Error: log file /users/ab12345/htcondenser/examples/dag_example_common/./diamond.dag.nodes.log on NFS **** condor_scheduniv_exec.578172.0 (condor_DAGMAN) pid 601659 EXITING WITH STATUS 1
This is telling you that you cannot put the DAG file (and therefore its log/output files) on a Network File Storage (NFS) due to the number of frequent writes. Instead put it on /storage or /scratch.
But I want XYZ!¶
Log an Issue, make a Pull Request, or email me directly.
I want to help¶
Take a look at CONTRIBUTING.